Stateless Logic

Restrictions From State
State is some form of "global" or "shared" memory. It allows code to "remember" or "know" something without having to be retold that fact every time. For instance, let's consider a simple count method which tracks how many times the method was called. Below is an example using state:
// C++20
// This global variable is our state
User user = User{
.name = "John Doe",
.email = "[email protected]",
.age = 12,
.creditCard = std::nullopt
};
auto user_can_buy_things() -> bool {
return !user.email.empty() && user.age >= 13 && user.creditCard.has_value();
}
The above example is fairly straightforward to understand. We have a global variable which keeps track of the current user. We then call a method which checks if a user has an email address and credit card, and if they're old enough to make purchases. If we wanted to change things, then we would change the global variable.
This method works fine, so long as we use it only in the specific use case that the state was designed for. Here, we're using a non-thread safe global variable. So, we can only use the counter in a non-threaded context. Additionally, we're using program memory to store the state, so the state lifetime is tied to program lifetime. This means if we restart the program, then our state will get reset.
Here is another example of a stateful system.
function userCanBuyThings(dbConnPool, userId) {
const conn = dbConnPool.getConnection();
try {
const res = conn.execute(
'SELECT email, age, creditCard FROM user WHERE id = :id',
{id: userId}
)[0];
return res.email && res.age >= 13 && res.creditCard !== null;
}
finally {
conn.releaseToPool();
}
}
In this example, we are no longer using a global variable. Instead, we are using an SQL database. This means that we can use both multiple threads and mutliple servers, and the DB will (mostly) handle synchronization for us. However, this method does require that we must have a database instance setup, and that the database must understand our SQL dialect (we're using pretty basic SQL here, so that shouldn't be an issue, but somtimes it is), and that our code has a way to connect to the database (we have a user with the right permissions). It also means we cannot use our method without a database.
However, since we're using a database that means our state lifetime is tied to the database. We can restart our program without losing state. We can also change the state from anywher by writing to the database. But if we reset our database or restore from a backup, then we will reset our state.
In both cases, we have extremely specific requirements on when and how our method will be usable. We also have restrictions about when and where we can use the state and how long the state will last. We either need to avoid threads, or we need a database. We tie the lifetime to the program, or we tie it to the database. If we need some other form of state (e.g. local file, Redis cache, AI data lake, encrypted storage, etc.) then we need to create a new copy that uses the new state.
If we know for sure that our logic will only ever be used for all eternity within the confines that our state provides, then we can couple state without logic and all will be good and the rest of this article isn't helpful.
I personally don't possess that level of knowledge about future events. You probably don't either since if you did, you probably wouldn't be reading this post at all. If we did have that knowledge, we'd either be saving the world or getting rich off the stock market and crypto. So, knowing that I don't have that kind of knowledge about the future, and assuming you don't either, let's talk about how we can isolate our logic from the restrictions imposed by state.
Stateless Liberation (with caveats)
We've looked at some examples of stateful functions (functions that use state). The state allows our code to "know" things which it wasn't told. So, how do we write code that doesn't have state? The answer is simple. Our code knows only what we tell it, and we tell it everything it needs to know. For instance, a stateless "can buy things" method would look something like the following:
auto user_can_buy_things(const User& user) -> bool {
return !user.email.empty() && user.age >= 13 && user.creditCard.has_value();
}
Or it could look like the following if we didn't want to tie it to the User object (we'll talk more about objects vs fields later):
auto user_can_buy_things(
const std::string& email,
int age,
const std::optional<CreditCard>& creditCard
) -> bool {
return !email.empty() && age >= 13 && creditCard.has_value();
}
Instead of our method "knowing" what it needs, we tell it what it needs. By passing in the data, we decouple our logic from our state, which also decouples our logic from the restrictions and lifetime of the state. This allows us to write different wrappers with different ways of tracking state. Below are some examples:
User currentUser = User {
.name = "John",
.email = "[email protected]",
.age = 13,
.creditCard = std::nullopt
};
auto current_user_can_buy_things() -> bool {
return user_can_buy_things(
currentUser.email,
currentUser.age,
currentUser.creditCard
);
}
auto user_id_can_buy_things(db::conn& dbConnection, int userId) {
const auto user = conn.execute(
"SELECT * FROM users WHERE id = :id",
{{"id", counterId}}
).at(0);
return user_can_buy_things(
user.col("email"),
user.col("age").as<int>(),
user.col("card").as<CreditCard>()
);
}
auto counter_microservice(UserService& userService, int userId) {
const auto user = userService.getById(userId);
return user_can_buy_things(user.email, user.age, user.creditCard);
}
There is a caveat though. Most flows through our application are defined in terms of "stateful" action. For example, usually a user flow would be described as "The current user clicks on the buy button, and if they don't have a card on file prompt them to enter card information". Then, most test cases and "deliverable" metrics are based around that stateful flow. This lends to a natural tendency by developers to write stateful code. This code may look similar to the following:
auto verify_can_purchase() -> bool {
const auto currentUserId = Session::instance()->get_current_user_id();
const auto currentUser = UserRepository::instance()->get_by_id(currentUserId);
if (!currentUser.creditCard.has_value()) {
// Return based on if they entered a card or not
return Dialogs::instance()->get_card_information();
}
return true;
}
Code like the above is natural in that it both matches the "user flow" description, and we can write tests which "match" that description (though these "tests" really mock away most of the code that's actually ran). To make something stateless requires developers to do more thought into separating the "logic" from the "state" in these user descriptions. It's also more unsettling for many developers because they can't write tests which "test the whole flow" (though they never write those tests anyway since, again, they are mocking away most of the code - they just think they're testing the flow).
This "unintuitiveness" and appearance "of not testing the whole flow" are the biggest drawbacks of stateless logic. We'll address these more, but it's important going into the conversation to be aware of these arguments against separating out since they will appear many times throughout the code. Many readers (possibly even including you) will have moments where you think "hey, but that doesn't let us write tests for this flow", or "there's no guarantee that this data is correct" or "the code doesn't say where this data comes from". Those aspects of stateless logic are intentional. With stateless logic, we're only testing the logic portion. We're only writing and reading the logic portion. The where, how, and why of the data is a separate concern that the logic portion won't (and shouldn't) care about.
Better debugging and testing
Debugging and testing stateless logic is a lot easier than debugging and testing stateful systems. For one, we can just capture/log the inputs in production and then replay those inputs in dev to get the same output. There isn't any "trying to make an account close that's close" or "trying to reproduce on a production account without messing things up" or "there's no way to test/reproduce". Since all the code knows is what it's told, we just need to know what it was told in production, and then we can retell it in development. And since we can retell it in development, we can codify the issue in our tests to avoid future regressions.
The hypothetical business we're working for deals with loan servicing. We just received a bug report for the method which evaluates whether a late fee should be charged. Late fees should be charged if 1) a loan is past due and 2) we are not currently in a grace period. A loan becomes past due if a borrower doesn't pay the amount that's due (e.g. they didn't pay their car payment). A grace period is the number of days a borrower can be late before getting charged (e.g. their car payment is due on the 1st, but they won't get charged a late fee if they pay by the 3rd).
Late fees also only get charged at the start of a day. To accomplish this, the software we're working in runs the late fee code as part of a chron job which starts at midnight. The late fee code does not get ran any other way.
Debugging with state
The bug report says "Late fees are being charged when they shouldn't. Tested with grace period of 5 days".
Below is the current implementation we're dealing with:
bool should_charge_late_fee(const LoanId& loanId) {
auto loan = LoanDbRepository::query_by_id(loanId);
const auto currentDate = Date::from(
std::chrono::time_point{
std::chrono::system_clock::now()
}
);
const auto paymentDate = PaymentService::query_by_id(loan.lastPaymentId).date;
return currentDate - paymentDate > loan.gracePeriodInDays;
}
There are also some tests for the method outlined below:
DEF_TEST("Negative Case") {
auto testLoanId = LoanId{"1234"};
auto testPaymentId = PaymentId("123");
auto loanMock = Mocker::CreateMockObject<Loan>()
->create_instance()
->set_property<&Loan::gracePeriodInDays>(5)
->set_property<&Loan::getClosestDueDate>(Date::from("2020-01-01"));
auto paymentMock = Mocker::CreateMockObject<Payment>()
->create_instance()
->set_property<&Payment::dateInDays>(Date::from("2020-01-02"));
auto loanDbMock = Mocker::CreateMockObject<LoanDbRepository>()
->mock_static<&LoanDbRepository::query_by_id>()
->when_called_with(testLoanId)
->will_return(mockLoan);
auto paymentDbMock = Mocker::CreateMockObject<PaymentService>()
->mockStatic<&PaymentService::query_by_id>()
->when_called_with(testPaymentId)
->will_return(paymentMock);
auto chronoMock = Mocker::CreateMockFunction<std::chrono::system_clock:now>()
->when_called_with()
->will_return(Date::from("2020-01-03"));
ASSERT_FALSE(should_charge_late_fee(testLoanId, testPaymentId));
}
DEF_TEST("Positive Case") {
auto testLoanId = LoanId{"1234"};
auto testPaymentId = PaymentId("123");
auto loanMock = Mocker::CreateMockObject<Loan>()
->create_instance()
->set_property<&Loan::gracePeriodInDays>(5)
->set_property<&Loan::getClosestDueDate>(Date::from("2020-03-01"));
auto paymentMock = Mocker::CreateMockObject<Payment>()
->create_instance()
->set_property<&Payment::dateInDays>(Date::from("2020-01-01"));
auto loanDbMock = Mocker::CreateMockObject<LoanDbRepository>()
->mock_static<&LoanDbRepository::query_by_id>()
->when_called_with(testLoanId)
->will_return(mockLoan);
auto paymentDbMock = Mocker::CreateMockObject<PaymentService>()
->mockStatic<&PaymentService::query_by_id>()
->when_called_with(testPaymentId)
->will_return(paymentMock);
// Have the date be past the due date
auto chronoMock = Mocker::CreateMockFunction<std::chrono::system_clock:now>()
->when_called_with()
->will_return(Date::from("2020-06-01").to_chrono());
ASSERT_TRUE(should_charge_late_fee(testLoanId, testPaymentId));
}
Not a lot of useful testing going on there. It's pretty hard to read with the mocking code, but it looks like they're just testing two dates, that's super close to the payment/due date, and one that's super far from the payment/due date. If we run the code it passes (no surprise there).
So, whatever the issue is, it's not covered by the tests. Let's now see if we can reproduce the issue. To do that, we need to create test data. Ideally, we want test data that's both realistic (it has on-time payments, early payments, missed payments, partial payments, etc.) and doesn't require us to do weird stuff with our clock to test our method (we do rely on the current time).
We look through the developer tools, and there isn't a way to generate test data. There also isn't a way to import sample data from other environments (e.g. import the data which caused the bug report). Instead, devs have to manually create their test data using the UI. This sort of setup is pretty common, but it does make testing edge cases and bug reports quite a bit harder. Especially since the only time this method runs naturally is at midnight.
Let's create a few different loans and let them run for a few days to see what happens. We do need to get past the due date before our code really runs. Fortunately, most loan systems allow entering "old" or "historical" data, so we don't have to create "new" loans with the first due date being a month out. Instead, we'll create loans that are a month old with the first due date being today. We'll also add in any payments on the day they apply, that way it resembles what a user will experience. Our results are in Table 1.
| Days past due date (Grace period of 5) | Paid in full | Partial payment | Late payment (by 1 day) | Late payment (by 7 days) | No payment |
|---|---|---|---|---|---|
| 0 | no fee | no fee | fee | fee | fee |
| 1 | no fee | no fee | no fee | fee | fee |
| 2 | no fee | no fee | no fee | fee | fee |
| 3 | no fee | no fee | no fee | fee | fee |
| 4 | no fee | no fee | no fee | fee | fee |
| 7 | fee | fee | no fee | no fee | fee |
| 8 | fee | fee | fee | no fee | fee |
| 9 | fee | fee | fee | no fee | fee |
| 10 | fee | fee | fee | no fee | fee |
| 11 | fee | fee | fee | no fee | fee |
| 14 | fee | fee | fee | fee | fee |
You'll also notice that it took 14 days to get the above table. While we ran 5 tests, it took 14 days before everything reached a stable equilibrium (meaning that nothing would change for additional days).
Looking at the table, it looks like we charge a late fee five days after the last payment date. That five days lines up with our grace period length. Now that we know what the issue is, we can try to reproduce it in our test cases. Let's do this by changing our negative test case to have a current date just after the grace period ends.
DEF_TEST("Negative Case") {
auto testLoanId = LoanId{"1234"};
auto testPaymentId = PaymentId("123");
// excluding for brevity
auto chronoMock = Mocker::CreateMockFunction<std::chrono::system_clock:now>()
->when_called_with()
->will_return(Date::from("2020-01-06")); // Changed this line here
// Assertion now fails
ASSERT_FALSE(should_charge_late_fee(testLoanId, testPaymentId));
}
Now we're on to something!
Looking back at our code, it looks like our method is indeed basing everything off of the last payment date. This means we are always charge late fees five days after a borrower paid! Let's change this so that we only charge if there is not a payment within the grace period.
bool should_charge_late_fee(const LoanId& loanId) {
const auto currentDate = Date::from(
std::chrono::time_point{
std::chrono::system_clock::now()
}
);
const auto loan = LoanDbRepository::query_by_id(loanId);
const auto paymentDate = PaymentService::query_by_id(loan.lastPaymentId).date;
const auto dueDate = loan.getClosestDueDate();
const auto endOfGrace = dueDate + loan.gracePeriodDays;
const auto inGracePeriod = currentDate <= endOfGrace;
const auto paidByEnd = paymentDate < endOfGrace;
return !inGracePeriod && paidByEnd;
}
If we rerun our failed test case it now passes! Does that mean we're done? Not quite. Let's rerun our 14-day manual test and see what we get.
Unfortunately, our other test data has already aged out of usefulness. We're no longer able to test the in-grace period and post-grace period for those loans, and that's the bit which we're changing. This is pretty common in software development, unfortunately. We'll learn how to address this later on, but for now we have to create an additional 5 loans and rerun our 14-day test. The results are in Table 2.
| Days past due date (Grace period of 5) | Paid in full | Partial payment | Late payment (by 1 day) | Late payment (by 7 days) | No payment |
|---|---|---|---|---|---|
| 0 | no fee | no fee | no fee | no fee | no fee |
| 1 | no fee | no fee | no fee | no fee | no fee |
| 2 | no fee | no fee | no fee | no fee | no fee |
| 3 | no fee | no fee | no fee | no fee | no fee |
| 4 | no fee | no fee | no fee | no fee | no fee |
| 7 | no fee | no fee | no fee | fee | fee |
| 8 | no fee | no fee | no fee | fee | fee |
| 9 | no fee | no fee | no fee | fee | fee |
| 10 | no fee | no fee | no fee | fee | fee |
| 11 | no fee | no fee | no fee | fee | fee |
| 14 | no fee | no fee | no fee | fee | fee |
The biggest issue is that our function is depending on the current time, so manual tests are limited in speed by time itself. But maybe they don't have to be. Maybe we can separate our logic from time itself.
Separating from time
The first step to separate our logic from time is to stop querying the current time and instead receive the current time. The change would look like the following:
bool should_charge_late_fee(const LoanId& loanId, const Date& currentDate) {
const auto loan = LoanDbRepository::query_by_id(loanId);
const auto paymentDate = PaymentService::query_by_id(loan.lastPaymentId).date;
const auto dueDate = loan.getClosestDueDate();
const auto endOfGrace = dueDate + loan.gracePeriodDays;
const auto inGracePeriod = currentDate <= endOfGrace;
const auto paidByEnd = paymentDate < endOfGrace;
return !inGracePeriod && paidByEnd;
}
With this change, we can now start "scrubbing" time by easily changing the "current" date. We could even create a little developer-only UI tool on a loan to make changing the date easier.

| Days past due date (Grace period of 5) | Paid in full | Partial payment | Late payment (by 1 day) | Late payment (by 7 days) | No payment |
|---|---|---|---|---|---|
| 0 | no fee | no fee | no fee | no fee | no fee |
| 1 | no fee | no fee | no fee | no fee | no fee |
| 2 | no fee | no fee | no fee | no fee | no fee |
| 3 | no fee | no fee | no fee | no fee | no fee |
| 4 | no fee | no fee | no fee | no fee | no fee |
| 5 | no fee | no fee | no fee | no fee | no fee |
| 6 | no fee | no fee | no fee | fee | fee |
| 7 | no fee | no fee | no fee | fee | fee |
| 8 | no fee | no fee | no fee | fee | fee |
| 9 | no fee | no fee | no fee | fee | fee |
| 10 | no fee | no fee | no fee | fee | fee |
| 11 | no fee | no fee | no fee | fee | fee |
| 14 | no fee | no fee | no fee | fee | fee |
The most prominent issue is the field "lastPaymentId" on the loan. Table 4 shows a sample payment schedule for a loan.
| Date | Activity |
|---|---|
| 2022-01-01 | Due Date |
| 2022-01-01 | Payment Made |
| 2022-02-01 | Due Date |
| 2022-03-01 | Due Date |
| 2022-03-02 | Payment Made |
| 2022-03-09 | Payment Made |
This highlights a common issue with mixed state logic and time travel debugging, if only part of the logic is stateless or only part of the state can time travel, then time travel debugging won't always work properly. But don't worry, we'll fix this issue as part of our bug fix for the partial payments.
Fixing our original bug
The issue with our bug is we're checking payment dates. However, we really should be checking the outstanding balance on the loan. If we have an outstanding balance, then we should charge a late fee. If we don't have a balance, then we won't charge a fee.
For our fix, we do need to get the series of payments and charges on the loan up to the current date. We'll also take this opportunity to remove our database calls by passing in the loan object directly. Here is what the code might look like:
bool should_charge_late_fee(const Loan& loan, const Date& currentDate) {
const auto dueDate = *std::find_first_of(
// This iterates in reverse order,
// so "find_first_of" is really "find_last_of"
loan.charges.rbegin(),
loan.charges.rend(),
// We're checking grace period, so we want
// the last date less than or equal to the current date
[currentDate](const auto& charge) {
return charge.date <= currentDate;
}
);
const auto inGracePeriod = currentDate <= dueDate + loan.gracePeriodDays;
if (inGracePeriod) {
return false;
}
// See if we've fallen behind
// We haven't missed a date, but we could be behind
const totalChargeToDate = std::transform_reduce(
loan.charges.begin(), loan.charges.end(),
std::plus{},
[¤tDate](const ChargeDate& charge) {
// Don't count charges which haven't happened yet
if (charge.date <= currentDate) {
return charge.amount;
}
return 0;
}
);
const totalPaidToDate = std::transform_reduce(
loan.payments.begin(), loan.payments.end(),
std::plus{},
[](const Payment& payment) {
// Don't count payments which haven't happened yet
if (payment.date <= currentDate) {
return payment.amount;
}
return 0;
}
);
return totalPaidToDate < totalChargeToDate;
}
Notice how we filter out the charges and payments by the current date? This allows us to actually have a time travel debugging tool where we can see and test the loan on a previous date. That way we can make and publish a simple UI tool to switch the "current" date of a loan.
However, there are a lot of different pieces of logic going on now. We're calculating the previous due date, the total charged, and the total paid. While those numbers are needed, they probably shouldn't be trapped inside the "should charge fee" method. In fact, there are several use cases where we need to calculate the outstanding balance, such as showing the minimum payment a borrower needs to pay for a pay cycle (especially useful if they paid extra the month before). So let's split the code up into smaller segments.
auto previous_due_date(const Loan& loan, const Date& currentDate) -> std::optional<Date> {
const auto it = std::find_first_of(
// This iterates in reverse order,
// so "find_first_of" is really "find_last_of"
loan.charges.rbegin(),
loan.charges.rend(),
// We're checking grace period, so we want the last
// date less than or equal to the current date
[currentDate](const auto& charge) {
return charge.date <= currentDate;
}
);
if (it == loan.charges.rend()) {
return *it;
}
return std::nullopt;
}
auto total_charged(const Loan& loan, const Date& currentDate) -> double {
double total = 0;
for (const auto& charge : loan.charges) {
if (charge.date > currentDate) {
break;
}
total += charge.amount;
}
return total;
}
auto total_paid(const Loan& loan, const Date& currentDate) -> double {
double total = 0;
for (const auto& payment : loan.payments) {
if (payment.date > currentDate) {
break;
}
total += payment.amount;
}
return total;
}
auto outstanding_balance(const Loan& loan, const Date& currentDate) -> double {
return total_charged - total_paid(loan, currentDate);
}
auto should_charge_late_fee(const Loan& loan, const Date& currentDate) -> bool {
const auto dueDateOpt = previous_due_date(loan, currentDate);
if (!dueDateOpt.has_value()) {
// Nothing has come due yet, so no late fee
return false;
}
const auto inGracePeriod = currentDate <= dueDate.value() + loan.gracePeriodDays;
if (inGracePeriod) {
return false;
}
// See if we've fallen behind
// We haven't missed a date, but we could be behind
const balance = outstanding_balance(loan, currentDate);
return balance > 0;
}
| Days past due date (Grace period of 5) | Paid in full | Partial payment | Late payment (by 1 day) | Late payment (by 7 days) | No payment |
|---|---|---|---|---|---|
| 0 | no fee | no fee | no fee | no fee | no fee |
| 1 | no fee | no fee | no fee | no fee | no fee |
| 2 | no fee | no fee | no fee | no fee | no fee |
| 3 | no fee | no fee | no fee | no fee | no fee |
| 4 | no fee | no fee | no fee | no fee | no fee |
| 5 | no fee | no fee | no fee | no fee | no fee |
| 6 | no fee | fee | no fee | fee | fee |
| 7 | no fee | fee | no fee | fee | fee |
| 8 | no fee | fee | no fee | fee | fee |
| 9 | no fee | fee | no fee | fee | fee |
| 10 | no fee | fee | no fee | fee | fee |
| 11 | no fee | fee | no fee | fee | fee |
| 14 | no fee | fee | no fee | fee | fee |
Simplifying the Interface
We have removed the dependence of our code on both the database and the system clock. We also set up time travel debugging for our code. Now it's time to write our tests.
Because of our changes, we no longer need to mock anything. Instead, we can just create test data and pass it in. Our tests now look like the following:
DEF_TEST("No payment made") {
auto loan = Loan {
.id = LoanId{"14938020394"},
.initialPrincipal = 1000.00,
.paymentPeriodType = PAYMENT_PERIOD_TYPE::MONTHLY,
.firstPeriod = Date::from("2024-01-01"),
.paymentPeriods = 36,
.interestRate = 0.06,
.periodPayment = 30.42,
.gracePeriodInDays = 5,
.lateFeeAmount = 20.50,
.payments = {
{
.id = PaymentId{"94829"},
.date = Date::from("2024-01-01"),
.amount = 30.42
},
{
.id = PaymentId{"94848"},
.date = Date::from("2024-02-01"),
// Didn't pay the full amounts, late fee should be charged
.amount = 20.42
},
{
.id = PaymentId{"94848"},
.date = Date::from("2024-02-20"),
// Finished paying the full amount (resets for next period)
.amount = 10.00
},
{
.id = PaymentId{"94862"},
.date = Date::from("2024-03-01"),
.amount = 30.42
},
// No april payment, late fee should be charged.
{
.id = PaymentId{"94896"},
.date = Date::from("2024-05-01"),
// Account comes back to current
.amount = 60.84
}
}
};
// We'll calculate the charge dates out so that
// we don't have to write them by hand
// If we wanted to test the charge date calculations,
// we'd do that in another set of tests
loan.calculate_charge_dates();
auto apr1 = Date::from("2024-04-01");
auto apr30 = Date::from("2024-04-30");
auto endOfGrace = apr1 + loan.gracePeriodDays;
for (size_t date = apr1; date <= endOfGrace; ++date) {
ASSERT_FALSE(should_charge_late_fee_stateless(loan, date));
}
for (size_t date = endOfGrace; date <= apr30; ++date) {
ASSERT_TRUE(should_charge_late_fee_stateless(loan, date));
}
}
Well, we got rid of mocks, but we didn't make our tests more readable. In fact, we might have made our test cases less readable due to how big and complex our loan object is.
We could mock out our loan object and then set the fields we need, but that doesn't solve the underlying issue. So, what is the underlying issue?
We are relying on a complete loan object when we only need a few fields. Let's look at our code again and label the data we actually need:
auto should_charge_late_fee(const Loan& loan, const Date& currentDate) -> bool {
// Need the previous due date
const auto dueDateOpt = previous_due_date(loan, currentDate);
if (!dueDateOpt.has_value()) {
return false;
}
// Need the length of the grace period & the current date
const auto inGracePeriod = currentDate <= dueDate.value() + loan.gracePeriodDays;
if (inGracePeriod) {
return false;
}
// Need the outstanding balance
const balance = outstanding_balance(loan, currentDate);
return balance > 0;
}
We only need four input parameters to our method. Four parameters isn't a lot, and it drastically cuts down on the number of fields our test code needs to initialize. Let's refactor our method signature to only take in the parameters we need.
auto should_charge_late_fee(
const std::optional<Date>& previousDueDate,
int gracePeriodDays,
double balance,
const Date& currentDate
) -> bool {
if (!previousDueDate.has_value()) {
// Nothing has come due yet, so no late fee
return false;
}
// See if we are in the grace period
const auto endOfGrace = previousDueDate.value() + gracePeriodDays;
const auto inGracePeriod = currentDate <= endOfGrace;
if (inGracePeriod) {
return false;
}
// See if we have an outstanding balance
return balance > 0;
}
If we want to save lines of code, we could also have rewritten it as follows:
auto should_charge_late_fee(
const std::optional<Date>& previousDueDate,
int gracePeriodDays,
double balance,
const Date& currentDate
) -> bool {
// Something must have come due for us to charge a late fee
return previousDueDate.has_value() &&
// And we must be outside the grace period
currentDate > previousDueDate.value() + gracePeriodDays &&
// And we must have an outstanding balance
balance > 0;
}
DEF_TEST("should charge late fee") {
const int grace = 5;
const auto apr1 = Date::from("2024-04-01"); // due date
const auto apr5 = Date::from("2024-04-05"); // last day of grace
const auto apr6 = Date::from("2024-04-06"); // first day after grace
const auto apr30 = Date::from("2024-04-30"); // way past grace
SUBCASE("Paid in full") {
const double balance = 0.0;
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr1));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr5));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr6));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr30));
}
SUBCASE("Partial Payment/No Payment") {
const double balance = 10.0;
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr1));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr5));
ASSERT_TRUE (should_charge_late_fee(apr1, grace, balance, apr6));
ASSERT_TRUE (should_charge_late_fee(apr1, grace, balance, apr30));
}
SUBCASE("Late payment by one day") {
SUBCASE("Pre payment") {
const double balance = 20.0;
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr1));
}
SUBCASE("Post payment") {
const double balance = 0.0;
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr5));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr6));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr30));
}
}
SUBCASE("Late payment by eight days") {
SUBCASE("Pre payment") {
const double balance = 20.0;
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr1));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr5));
ASSERT_TRUE (should_charge_late_fee(apr1, grace, balance, apr6));
}
SUBCASE("Post payment") {
const double balance = 0.0;
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr30));
}
}
SUBCASE("Overpaid") {
const double balance = -200.0;
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr1));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr5));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr6));
ASSERT_FALSE(should_charge_late_fee(apr1, grace, balance, apr30));
}
}
If we take a look at the tests, we realize that we don't have to have a full loan to check our late fee.
We also don't have to be grabbing our data from the database at all. This means we could create a form which takes the input parameters and submits them to our code. This would allow both us and our coworkers (developers, QA, etcetera) to quickly test if the method is working. Additionally, the form could include a "Report Bug" button which would create a bug report that includes the input values. This would allow developers to quickly reproduce the issue.
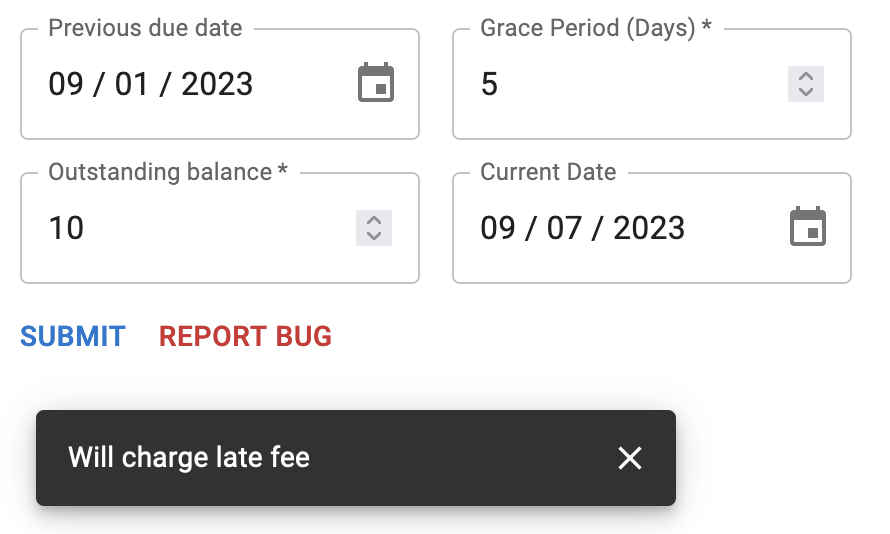
Other tools could be provided as well. For instance, a CSV reader could parse a CSV file and run it against the code. The CSV files could even replace manually written tests if desired, and it would let QA create and edit test cases easily.
Performance with stateless
One of the interesting side effects of relying on state is that our state is often the performance bottleneck. Database calls, filesystem reads, synchronization locks all add overhead. For simple requests, there aren't very many traps that will cause significant performance issues when coupling logic and state. However, when composing methods we can very quickly end up with additional overhead and non-trivial performance issues.
For this example, we'll be calculating the loan payment amount, and then we'll create a solver for the interest rate. The formula to calculate a loan payment is as follows:
Where is the Principal Value (or just the principal), is the interest rate per period (not the annual interest rate), and is the number of periods (not the number of years). For loans with monthly payments, is the annual interest rate divided by 12 and is the number of years multiplied by 12.
For this example, we'll assume all loans are defined with monthly periods. We'll also assume loans have the following fields:
- id (string) - The ID of the loan
- numYears (double) - The number of years for the loan
- annualInterest (double) - The annual interest rate (between 0 and 1)
- principal (double) - The principal value of the loan
function loanPayment(id: string) : number {
const loan = DB.connection()
.query_one(
"SELECT * FROM loans WHERE id = :id",
{id}
);
const r = loan.annualInterest / 12;
const n = loan.numYears * 12;
const Pv = loan.principal;
return (r * Pv) / (1 - Math.pow(1 + r, -n));
}
Nothing too complex here. We query a loan by ID, pull out the values we need, and then run it through the equation.
Now comes the tricky part. We want to create a payment solver where we adjust the interest rate until we get a payment amount inside some range.
There are formulas for getting the number of periods needed to get a payment, and there are formulas for getting the principal balance to get a formula, but I haven't found a formula to solve for the interest rate (let me know if you do happen to have one). Instead, I have an algorithm for searching for the interest rate.
Basically, we do a binary search between the numbers 0 and 1 (a 10% interest rate is represented by 0.1). We narrow the search range until we either get a payment that's inside the range, our number isn't changing (meaning we've reached the precision limit of doubles), or we exceed an iteration threshold (something like 500 or 1,000). To make things a little faster, we can optionally provide an initial guess (e.g. 0.1), that way we aren't spending the first few iterations going 1, 0.5, 0.25, etc.
The initial implementation tries to use our existing payment calculator. Since our payment calculator requires a loan to be in the database, we need to use the database to track our current guess. Here is the implementation:
function solveInterstRate(
loanId: string,
minPayment: number,
maxPayment : number = minPayment
): bool {
const initialInterestRate = getInterestRateForLoan(loanId)
let max = 1
let min = 0
let payment = loanPayment(loanId)
let inRange = () => {
return payment <= maxPayment && payment >= minPayment
}
let count = 0
while (!inRange() && count++ < 500) {
if (!Number.isFinite(payment)) {
setInterestRateForLoan(initialInterestRate)
return false
}
const oldGuess = getInterestRateForLoan(loanId)
let newRate = 0
if (payment > maxPayment) {
max = oldGuess
newRate = (oldGuess + min) / 2
} else {
min = oldGuess
newRate = (oldGuess + max) / 2
}
if (oldGuess === newRate) {
// We got the closest doubles will let us get
return true
}
setInterestRateForLoan(newRate)
payment = loanPayment(loanId)
}
// If our iteration timed out, make sure we reset; otherwise return true
return inRange() || (setInterestRateForLoan(initialInterestRate) && false)
}
Since we're using the DB for loanPayment, we also need to use the DB for our interest rate calculation. The methods getInterestRateForLoan and setInterestRateForLoan also involve DB calls. The total number of DB calls we could make in this one method range from 3-1,500+. It's potentially a ton of DB calls. I've seen code similar to this in a production system, and it's a major performance and resource drain.
We'll now modify the code to be stateless. We'll start with the loan payment method. For a loan payment calculation, we don't need all the loan fields. We only need the fields principal, annualInterest and numYears. Let's have those fields be our parameters instead of the loan id. With that change, we end up with code like the following:
function loanPayment(
annualInterest: number,
principal: number,
numYears: number
) : number {
const r = loan.annualInterest / 12;
const n = loan.numYears * 12;
return (r * principal) / (1 - Math.pow(1 + r, -n));
}
With this method, we can now remove the DB calls from our search algorithm. Instead of using a database loan for tracking the interest rate, we'll just use a local variable. And instead of asking for a loan ID, we'll ask for the principal and number of years. Our new code will look like the following:
function solveInterstRate(
principal: number,
numYears: number,
minPayment: number,
maxPayment : number = minPayment,
initialGuess : number = 0
): bool {
let guess = initialGuess || 0.5
const calculatePayment = () => loanPayment(guess, principal, numYears)
let payment = calculatePayment()
const inRange = () => {
return payment <= maxPayment && payment >= minPayment
}
let max = 1
let min = 0
let count = 0
while (!inRange() && count++ < 500) {
if (!Number.isFinite(payment)) {
return null
}
const oldGuess = guess
if (payment > maxPayment) {
max = guess
guess = (guess + min) / 2
} else {
min = guess
guess = (guess + max) / 2
}
if (guess === oldGuess) {
// We got the closest doubles will let us get
return true
}
payment = calculatePayment()
}
return inRange() ? guess : null
}
Now are code doesn't make any database calls! This helps us avoid a massive performance penalty.
Natural performance issues with stateful logic
I've seen quite a bit of code that loops over a method calls that do both a calculations and database queries. However, I've seen a much more common (and subtle) pattern for performance degradation with stateful logic. This type of code happens quite regularly in systems with Dependency Injection (DI).
Usually in DI systems, there are repository objects[1] which handle getting the state of some entity or a group of entities. Repository objects usually fetch the entities from a remote resource, such as a database or a microservice.With DI, repository objects are trivial to inject. Repository objects also tend to provide convenient methods to convert ids to instances of objects. Because repository objects are easy to get with DI, developers will sometimes start using ids as function parameters rather than receiving a full object instance (or even just the fields they depend on). Developers will then inject the repository objects, use them to "convert" the ids into an instance, and then run the business logic on the fetched object.
Early on in a project this doesn't matter too much. Greenfield projects often start with writing CRUD operations (update user by id, get user by id, etc.). Later on in the project, developers start combining the existing stateful methods to make more complex logic (get all non-admin users and send them a notification email, generate a report on the number of posts made per user by country, etc.). When smaller chunks of stateful logic are reused as part of a bigger flow, the application code will start making duplicate database calls as well as a lot of fragmented database calls. Over time, as more and more complex logic evolves on top of the existing stateful logic, the amount of database calls can create noticeable slowdowns for end users.
Let's look at a quick example. Let's say we were making a Reddit competitor, and we wanted to let moderators email all non-moderators on a subreddit. Our codebase uses DI, and most methods take identifiers as parameters (subreddit id, user id, etc.). Our code would look something like the following:
class ModeratorToolService {
#[Inject]
public AuthService $authService;
#[Inject]
public UserRepository $userRepository;
#[Inject]
public Session $session;
#[Inject]
public SubRedditAssociationRepository $subRedditAssoociationRepository;
#[Inject]
public EmailService $emailService;
public function emailNonModeratorsOnSubReddit(string $subject, string $content) {
$subRedditId = $this->session->subReddit();
$isMod = $this->authService->isModerator(
$this->session->user(),
$subRedditId
);
if (!$isMod) {
throw new UnauthorizedException();
}
$userIds = $this->subRedditAssoociationRepository
->userIdsOnSubReddit($subRedditId));
foreach ($userIds as $userId) {
if ($this->authService->isModerator($userId, $subRedditId)) {
continue;
}
// can't email users with invalid emails or who opted out
$user = $this->userRepository->getById($userId);
if (empty($user->email)
|| !$this->emailService->isValid($user->email)
|| $this->emailService->didOptOut($userId, 'notifications')
) {
continue;
}
$this->emailService->sendEmailTo($user->id, $subject, $content);
}
}
}
The performance issue with the above code is we are making tons of database calls. My rule of thumb is that any method which takes a resource id and then does something with the attached resource is going to have to retrieve that resource from the database at some point. Session data may also be stored in a database, so getting session data can also result in a database call.
From the above code, we can reasonably expect there to be a database call to get the session's subreddit, a database call to get the session's user, a database call to check the user's permissions, a database call to get the users tied to the subreddit, a database call per user to check permissions, a database call to get each user's information, a database call to see if the email address was flagged as invalid, a database call to see if the user had opted out of notifications, and a database call inside sendEmailTo to get the user's email. That's a lot of database calls.
We also already have a few duplicate database calls. For instance, we're getting all users tied to the subreddit, but we also have verified that the current user is tied to the subreddit. That means we've repeated some database queries for the current user. Additionally, we're currently getting the user information to verify the email address, and then we pass the user id to the email service. The email service is going to have to get the user information so that it can know which email address to send to. That results in another duplicate query for every user!
The problem only gets worse as we add more and more calls. For instance, we may add a feature where moderator changes to the subreddit's policies and guidelines results in a mass email to subreddit members. As part of that feature, we would have validated that the current user was a moderator for the subreddit before sending out the emails. However, our email code doesn't know that we already validated the user's permissions, so it has to rerun the database queries and revalidate the user.
If we had adopted a more "stateless" mentality, we could start de-duplicating the queries at the start of the request. Instead of having each class and method grab the current user's role, we could pass that in. Instead of our email service taking in a user id and then grabbing the user's email, we could pass in the user's email directly. These types of changes would allow for fewer database calls as well as more testable logic.
Streaming data with stateless
So far we've talked about a lot of the benefits of stateless code. But all of our examples have assumed that the data we're working with fits in memory. What happens when our data doesn't fit in memory? What if we need to stream our data from a database or a disk?
Even in these situations, stateless business logic can be achieved. The trick is to let the data streaming code live outside the logic handle streaming the data, and then provide a data collection abstraction to our logic code.
For instance, many languages have the concept of "iterators." Iterators allow developers to define a custom collection of values which can be iterated over in sequence. The iterated collection does not need to live in memory. In fact, iterators are often the most powerful when the full collection does not live in memory.
For this example, let's assume we wanted to process a list transactions to get the current balance. A simple, stateless, non-iterator approach may look like the following:
public static double balanceFrom(List<Transaction> transactions) {
return transactions.stream()
.mapToDouble(Transaction::amount)
.sum();
}
The above code works for any list of transactions which fit in memory. However, if we ever have to deal with a list which doesn't fit in memory, we will run into issues. Fortunately, we can replace our input List<Transaction> type with an Iterator<Transaction> type. Doing so would mean our method looks like the following:
public static double balanceFrom(Iterator<Transaction> transactions) {
return Stream.generate(transactions::next)
.mapToDouble(Transaction::amount)
.sum();
}
By using an iterator, we can still use an in-memory list when that's possible. This is useful for both performance in known small-scale case, but it's also incredibly useful for writing tests. And, by using an iterator we also can create a custom iterator which streams from the database. Below is what it might look like:
import java.util.*;
public class TransactionDbIterator implements Iterator<Transaction> {
private List<Transaction> buffer = null;
private int bufferIndex = 0;
private int page = 0;
private boolean hasNextPage = true;
private void fetchNextPage() {
// This is where our code does our database communication
// It will vary depending on your database and the query used
var result = TransactionRepository.fetchTransactions(page++);
hasNextPage = result.hasNextPage();
buffer = result.getTransactions();
bufferIndex = 0;
}
@Override
public boolean hasNext() {
if (buffer == null) {
fetchNextPage();
}
return hasNextPage || bufferIndex < buffer.size();
}
@Override
public Transaction next() {
if (buffer == null || bufferIndex >= buffer.size()) {
fetchNextPage();
}
return buffer.get(bufferIndex++);
}
}
The above code lets us iterate the database seamlessly. Our logic can treat it like any other iterator without ever knowing there are database calls being made. We can also test it independently, and we can switch where and how we are retrieving the data without ever having to touch our logic code.
We also don't need to use our custom iterator to test our business logic. We can still use a list in our tests like so:
@Test
public function testBalanceFrom() {
var list = List.of(
new Transaction(23),
new Transaction(-2),
new Transaction(-43),
new Transaction(42)
);
assertThat(Transactinos.balanceFrom(list.iterator())).isEqualto(20);
}
We can simplify the code quite a bit when generators are available. For instance, in PHP we could write something like the following:
// Our iterator as a generator
function dbIterator() : Generator {
$page = 0;
$empty = false;
while (!$empty) {
$buffer = TransactionRepository::getTransactions($page++);
$empty = true;
foreach ($buffer as $transaction) {
$empty = false;
yield $transaction;
}
}
}
// Sum everything
function balance(iterable $transactions) : double {
$balance = 0;
foreach ($transactions as $transaction) {
$balance += $transaction->getAmount();
}
return $balance;
}
// Sample test
function testBalanceFromTransactions() {
assertEquals(20, balance([23, -2, -43, 42]));
}
If your language has built in support for lazy sequences, we can use those to simplify the code as well. Below is an example in Clojure:
(defn sum-txs [txs]
(->> txs
(map :amount)
(reduce +)))
(defn tx-seq
([] (tx-seq 0))
([page] (lazy-seq
(cons (db/get-txs page)
(tx-seq (inc page))))))
If streaming data isn't available, we can also batch our calls to the logic code as well. We will have to have an extra step to combine the batch calls. The reduce step could also be broken out into a separate stateless function, that way we can test it easier. Below is an example:
fun sumTransactions(nums: List<Transaction>) : Double =
nums.sumOf { n -> n.amount }
fun reduceSums(accumulator: Double, current: Double): Double =
accumulator + current
fun batchSum(): Double {
var transactions : List<Transaction>;
var page = 0;
var total = 0.0;
do {
transactions = TransactionRepository.fetchTransactions(page++).transactions
total = reduceSums(total, sumTransactions(transactions))
} while (!transactions.isEmpty())
return total
}
Summary
We've explored different ways to separate business logic from state. By telling code what it needs rather than having it "know", we're able to simplify testing, remove mocks, and add better debugging tools to our codebase. Additionally, we can save ourselves in "hidden" costs when composing logic. We also showed different ways we can handle data streaming without coupling our business logic to our data store.
Logic does not need to be coupled with state. Separating the two does improve developer experience, code maintainability, and code reuse. Furthermore, we do not have to sacrifice performance to do so. We can either use the right abstractions to hide database calls from the logic, or we can batch calls to the logic and then combine the results separately. We've also shown that these concepts can be applied in a multitude of languages and paradigms, including C++, Java, Kotlin, TypeScript/JavaScript, PHP, and Clojure. We've also highlighted some language features that can help make different techniques easier to implement, such as implementing custom iterators, generators, and lazy sequences. We also showed some language-agnostic tooling that can be implemented around stateless code, including time-travel debugging, testing interfaces, and mock-less tests.
Bibliography
- [1] “Spring Boot @Repository,” ZetCode. https://zetcode.com/springboot/repository/ (accessed Sep. 7, 2023).