
Deadlocks and Starvation in JavaScript
Threads in the browser are still threads

Previously I showed how to share memory between threads and create mutexes inside of JavaScript. Which is really cool since it avoids the overhead of creating, queuing, and polling messages when passing simple data. And it can make it a lot easier for multiple threads to share data (the alternatives are broadcasting data or doing a map-reduce model).
However, not all is calm in multi-threading land. As soon as we bring multiple threads in, we get a whole host of problems (data races, logic races, starvation, etc.). And now that we’ve brought in locks, we get even more problems (deadlocks). Before we get too much further into all the cool ways to create primitives or to do cool things with threads, I wanted to take a step back. The rest of our journey will have many perils, so let’s rest and tell tales before continuing.
Starvation
Starvation is when greedy threads repeatedly take the resources from other threads, thereby blocking (or starving) them from making any progress. Signs of starvation include some threads perpetually hanging and some tasks being unusually delayed while other tasks are going through just fine. Another sign is tasks that are way too old to be running end up getting completed (and sometimes corrupting data) of more recent tasks.
Depending on the environment and severity, starvation can start to affect other resource uses than just CPU time or task completion time. Memory usage and disk usage can grow as work gets queued but threads don’t get resources to process them.
Thread starvation is related to thread contention, but in the way that starvation is a more serious (and dangerous) condition than contention. Contention is when all threads still make some progress, but many (or all) are getting slowed down by synchronization (aka. your program runs slower). Starvation is when the contention gets so out-of hand that some threads are unable to make any progress.
The risks and dangers of starvation is very real, even for massive tech companies. And, paradoxically, some of the same patterns that help with contention increase the risks of starvation.
Common Patterns which cause Starvation
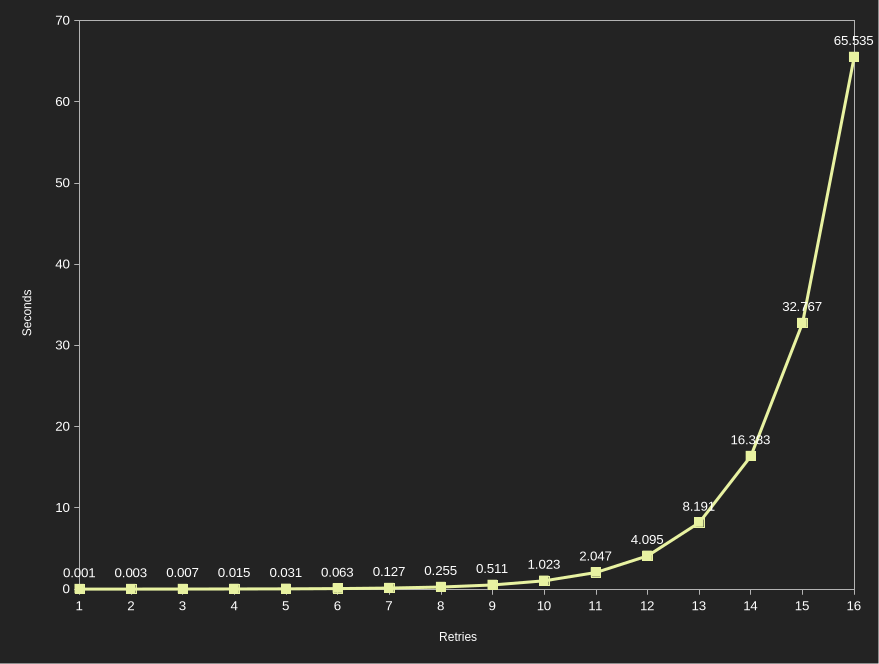
One such pattern is exponential back-off. The idea is simple, if a resource is highly shared, then having every thread constantly trying it can make every thread slower. Additionally, sometimes the resource has limits (rate limits, throughput limits, etc.) so hammering the resource at the same rate can overwhelm the resource. The most common solution to this is to simply “back-off” with longer and longer time gaps, that way if the resource is contended we give it additional time to be in a non-contended state. Often this is achieved by doubling (or some other constant multiplication) the wait period. The doubling is why this is called “exponential” back-off as the wait period grows exponentially, which decreases the load on the contended resource massively. Sounds good, right?
Well, almost. What happens when a resource is highly contended? What happens when a resource is locked 80% or 90% or 99% of the time? In these scenarios, when a thread tries to get a lock, it will fail to get a lock 80% or 90% or 99% of the time. If it fails to get a lock, it will wait longer and longer between each retry.
Exponential back-offs become very long very quick. At an initial 1ms delay and a doubling each time, it only takes 10 retries before it’s been a full second. At 1 second, modern CPUs have wasted 3-4 billion cycles. After 16 retries, it’s been over a minute. That’s 180-240 billion cycles.
Another common cause is simply over-allocating threads or over sharing data between threads. More threads doesn’t always make things faster, and instead can make things slower due to contention. The more threads, the more contention, and the more likely some poor thread gets repeatedly locked.
More shared data isn’t good either, and it may be more acceptable to duplicate and copy data than to share it. Generally, it’s best to minimize the amount of data shared between threads as much as possible.
Other common patterns involve overuse of read-write locks, over locking or locking for extended periods of time, and doing network requests or expensive computation tasks while locked.
Read-write locks are an optimization that sounds good (and is often very good for usual performance). However, they have a dark side too. Many read-write locks are not “fair” in that they don’t prioritize readers equally to writers. Instead, they will prefer one caste over the other - usually readers since they can be more concurrent. The segregation of read-write locks can cause massive issues if the preferred caste is extremely pervasive in usage. For instance, a read-preferring lock will starve write locks if there is always at least one active reader - a situation that can become very common in high-traffic scenarios.
Over locking is another issue where more locks are acquired than needed, or when locks are overused when simple atomic operations would have sufficed. Locks are blocking, and by being blocking they cause open up starvation points.
Holding locks for long periods of time also causes starvation. If a lock is held while performing expensive calculations or network requests, then that means no other thread can proceed until those calculations are done. If no other threads can proceed, then they end up creating a backlog of stuck threads. Stuck threads create contention, and that can lead to starvation.
Mitigations
The first mitigation is less about preventing starvation, and more about detecting it (and preventing it from causing outdated data to be propagated). It’s also rather simple: add enforced timeouts. If something takes too long, kill it and raise an alert. Get too many alerts, and there’s a starvation/high contention problem. The downside to this approach though, is that something you wanted to get done didn’t actually get done. That little fact can cause it’s own set of issues. But, in many scenarios, it’s far better for stale work to not get done then for it to get done and cause other issues.
A similar approach specific to retries (especially with exponential back-off) is to limit the number of retries allowed. If we only allow 5 retries before failing, then we guarantee we will succeed or fail in a fixed time period.
Another way to prevent starvation is to reduce contention. A simply solution is to reduce the number of threads (usually by using thread pools instead of spinning up a new thread per task). Other ways involve reorganizing code and memory access patterns to not require nearly as much sharing (prioritize independence over synchronization). Reducing the number of locks obtained (while maintaining correctness) also helps. Optimizing (or removing) work done in a locked section will help prevent threads from backing up. All of these strategies can involve new data structures (e.g. concurrent queues), large refactors of the code, or new algorithms and coding patterns (e.g. map-reduce).
Using wait-free algorithms and data structures can also help as they ensure that every thread makes progress. However, there are many drawbacks. Many wait-free algorithms have higher base latency, meaning a lock system with low contention can outperform a wait-free algorithm. Additionally, wait-free algorithms are hard to implement, hard to verify, and even harder to invent. Not every situation may have an appropriate wait-free solution.
Data Races
Data races are a very simple type of race condition. A program reads a value, modifies a value, and then that work becomes stale, and finally the stale value is written back.
Work becomes stale when another thread, process, or computer modifies the original value before the work was written back. We saw a very simple example earlier when adding to the same address from different threads. However, this type of problem can arise in much more complex code or environments. It can happen with outdated cache layers, contention at the database layer, lack of idempotence in event processing, and lack of locks inside a program.
Generally, data races simply occur when there aren’t enough locks around shared data (in memory or on disk). Often, the solution is to either add more locks or reduce the need for shared memory. However, that’s not the only solution.
One other solution is to use more “compare exchange” semantics. Basically, perform an atomic read, do the calculation, and then do a compare exchange to write the answer back only if the value didn’t change. If it did change, read it, recalculate, and retry. This approach is called “optimistic concurrency” in that it’s optimistic a lock won’t be necessary since the value rarely changes.1 Of course, only use optimistic concurrency when that holds true, as unfounded optimism can lead to headaches when debugging production issues.
One side note, out of all the issues that we’ll talk about today, data races is the only concurrency issue Rust addresses when they are limited to inside a program’s memory! Data races across servers, cache layers, and databases aren’t covered by Rust’s compile time detection as it has no insight into those systems. High contention, starvation, logic races, and deadlocks aren’t covered either.
Logic Races
Logic races are similar to data races in that some work is stale (or incorrect) based on the work another thread did. However, the difference is that the race condition didn’t happen because some memory was changed instead of being locked. Instead, it has to do with a mismatched ordering of systems or tasks running.
To help clarify this distinction, we’ll use an example. Suppose that Jim has $30 in his account. He goes to the bank and deposits a $200 check. Simultaneously he purchases a $60 game on his phone while the banker is processing the check. In a data race, we would get a sequence like the following:
Banker machine reads current balance of $30
Jim’s phone reads current balance of $30
Banker machine adds $200 to the balance resulting in $230
Jim’s phone deducts $60 from the balance resulting in ($30) and an overdraft fee
Banker machine writes $230 to the account
Jim’s phone writes ($30) to the account and an overdraft fee
In this scenario, Jim’s $200 disappeared due to a data race - the actual data of his balance was not properly locked.
Now, let’s look at a logic race. We have two possible scenarios.
Scenario 1
Banker machine lock’s Jim’s balance
Jim’s phone waits for lock
Banker machine updates Jim’s balance to $230 and unlocks
Jim’s phone locks Jim’s balance
Jim’s phone deducts $60, sets new balance to $170, and unlocks
Scenario 2
Jim’s phone locks’s Jim’s balance
Banker machine waits for lock
Jim’s phone sets Jim’s balance to ($30), adds an overdraft fee, and unlocks
Banker machine locks Jim’s balance
Banker machine sets Jim’s balance to $170 and unlocks
In this scenario, we still end up with the correct final balance of $170. But, in Scenario 1 Jim doesn’t have an overdraft fee, yet in Scenario 2 he does! This difference based on ordering of simultaneous events is called a logic race and is a separate type of race condition from data races. What’s even more insidious is they’re incredibly hard to detect ahead of time2, and very hard to replicate.
To make matters worse, the code often appears correct during code reviews, and the code will run correctly during testing since it is correct when ran sequentially (i.e. banker first, then Jim’s phone). These types of bugs can also lay hidden for years in a production system where simultaneous events are extremely rare. And tracking these types of bugs down can be downright maddening as they appear and disappear like phantoms in the night. Validating a fix is also almost impossible. How do you check that a bug which only occurs once in tens of millions of button clicks is actually fixed?
The other worst part of these bugs is adding any other synchronization step (debugger, printing or logging messages, allocating memory) can be enough to add a reliable-enough ordering to prevent the bug from appearing inside a development or test environment. Truly maddening stuff.
Deadlocks
Deadlocks are one of the most dreaded concurrency bugs as they don’t just affect one thread or one customer. They can bring entire systems and products to their knees.
A deadlock is a simple. Multiple threads get stuck waiting for a lock they will never get. This isn’t starvation where they won’t get it for a long, long time or there’s a small probability that they won’t get it. No. This is never. As in, not even with infinite time.
There are a few ways a deadlock can happen. The first, is that a thread never calls unlock on a lock. Often, this happens because either the thread threw an exception and didn’t have the unlock in a finally block, or because the thread unexpectedly terminated prematurely - bypassing the finally block altogether3. This is the easy case, both to create, find, and fix.
The other common way a deadlock happens is when multiple threads need multiple locks, but the way they try to get the locks causes errors.
For instance, assume we have two threads (1 and 2) and two locks (A and B).
Thread 1 acquires lock B
Thread 2 acquires lock A
Thread 1 does some work, but realizes it now needs lock A
Thread 1 blocks on lock A, waiting for Thread 2 to finish
Thread 2 does some work, but realizes it cannot finish without lock B
Thread 2 blocks on lock B, waiting for Thread 1 to finish
Both threads are now waiting for the other, but neither thread can finish
Congratulations! We just made a deadlock. And these types of deadlocks are really easy to create accidentally. In the above example, we were doing some work, but found we needed more locks than we originally had. When we tried to get them, we ended up getting blocked, forever.
Common Deadlock Patterns
Commonly, this type of deadlock I’ve ran into when dealing with typical Object Oriented Programming (OOP) and/or concurrent data structures. In OOP, there’s a very heavy emphasis on encapsulation where as much as possible is private. Often, this includes implementation details like locks. In OOP, there’s also this idea of reuse through interfaces and hierarchies. So when we pass a class as a parameter, we don’t actually pass it as that specific class. We pass it as a higher-level abstraction with no relation to the implementation. Meaning, the code calling the class has no idea if the method will block or not.
This means that we could end up having one thread start in class WorkQueue and then end up calling into class TaskProcessor, all while another thread starts in TaskProcessor and calls WorkQueue. And if both TaskProcessor and WorkQueue have class-wide locks, then we’ve made a deadlock!
Mitigations
Fortunately, there are mitigation strategies. First, having a thread lock everything it will (or will possibly) need at the start of a critical section can go a long way. It prevents the “I have resource A, but now I need B” scenario we saw. That said, when locking everything needed, make sure it’s done in the same order for every thread (i.e. lock A then B everywhere)! Otherwise, you’ll still end up with deadlocks.
For one, since we’re locking up-front, that means we haven’t done any critical work yet. So, if we fail to get even one lock, we simply unlock everything, wait for a random period of time (that way we minimize the chance we have contention on our next retry), and then retry to lock. This prevents deadlock (some thread can now make progress), but we could end up in starvation if we aren’t careful (one thread is in a constant unlock-and-retry cycle).
If we want a strategy that works regardless of whether we lock up-front or as needed, then we need to adjust things a little more. We can introduce a “try-lock” method. A “try-lock” will try to acquire a lock without blocking. If it fails to lock, it will throw an error (or return an error code/false boolean - all depends on your coding pattern!). We can now use this to retry acquiring the inner lock while doing a back-off with a retry limit. Again, this approach will cause some tasks to fail, but it’s better than blocking the whole system.
Another strategy is to add a timeout to every lock. That way, if we hit a deadlock, the system will abort the wait, we’ll unlock, and end with a failure. Not ideal to fail a task, but at least the system continues moving forward. Though, keep in mind that these timeouts will need to be short enough to prevent the whole system from stalling (as we still have a lock while we’re waiting), all while being long enough to prevent false positives (i.e. waiting on a resource that will be freed if we waited just a little longer).
Thrashing and Contention
These last two are more performance-related rather than “end the world” related. Threading does not automatically make programs faster. And, throwing more threads at the problem only works up to a point. After that, it makes things worse.
For one, adding more threads causes more contention on locks. More contention causes more waits, more waits increases the chance for starvation. However, contention and starvation aren’t the only issues with more threads.
There’s also thrashing.
CPUs only see the state of the currently running thread. The operating system uses some special hardware interrupts to schedule a switch to another thread. Switching to another thread involves unloading the memory of the current thread (the instructions/code, the registers, the cache, etc.), saving it off to memory, and then loading the other thread from memory. This process also clears out pipelines, and requires re-warming the CPU cache. This whole process is called “context switching.”
Context switching isn’t bad, it’s just a necessary part of having threads. It’s also a very slow or costly experience, so it’s best to minimize it.
Unfortunately, the more threads there are trying to do stuff, the more the operating system needs to trigger context switches, which means the slower everything goes. You may have noticed this when you open way too many applications at once, and they’re all trying to do stuff. The OS tries it’s best to schedule each one to do it’s work, but the time it takes the hardware to switch causes slow downs.
Overloading the hardware with context switches is “thrashing.” We’re basically beating down the hardware with so many context switches that it’s unable to get anything done.
Fortunately, modern CPUs and OS’s are actually really good at handling a lot of threads, so having slightly too many threads won’t make a big noticeable difference for us. However, trying to spawn hundred or thousands of threads definitely will cause issues.
The general rule of thumb is to spawn 1 - 2 threads per logical core4. 1 thread if it’s not going to be blocked waiting for I/O very often, 2 if it will be (that way one thread can work while the other is loading from disk).
So, how do we know how many logical cores there are? By using navigator.hardwareConcurrency - which is a number that tells us how many cores there are.
That said, on the web we have a little more to worry about. We don’t really want to go too high above the logical core count for our entire site. So if we’re using a lot of Worker we need to keep in mind how many active tabs or contexts the user will have at once. Whereas if we’re using a global SharedWorker we need to keep in mind how many legacy versions of the worker will be on the user’s machine at once.
For the Worker scenario, we may need to scale back our worker count or limit how many iframes we embed. For the SharedWorker we may need to consider forced refreshes of the site if the code gets too stale.
Wrap Up
We looked at a lot of different edge cases and issues that arise from multi-threaded programming. They aren’t impossible to deal with - code has been dealing with them for decades now. But, it’s also good to get familiar with the concepts at a high-level prior to diving head first into more complex multi-threaded programming.
Next time will be more about code rather than theory, as I’ll be going into some more synchronization primitives and their inner workings. I’ll first revisit the Mutex in more depth, and we’ll create an async version that uses promises instead of blocking a thread. We’ll also add timeouts to it as well.
For optimistic concurrency, it is very important that the calculation is side-effect free (e.g. doesn’t send emails or update the database record) as it will be ran repeatedly in a loop. Also, be wary with where it’s used. If optimistic concurrency is used where there are frequent writes to memory, then it could cause starvation as writes get continually stuck in recalculation loops!
Rust cannot detect logic races at compile time, only the easier data race subset.
For Rustaceans, think “a thread paniced while it held a lock.” Also, Rust doesn’t prevent deadlocks, and badly misplaced panics can cause deadlocks as it kills the thread and not the process.
Logical cores include things like hyper-threaded cores (basically a “virtual” core) that software can use. Since it’s what our code can use, it’s what’s generally what’s preferred in the software layer.